Fair Use, Copyright, and the Challenge of Memorization in the NYT vs. OpenAI

In the final days of 2023 the New York Times filed a lawsuit against OpenAI (and Microsoft) alleging that the models trained and deployed by OpenAI and Microsoft were infringing on its intellectual property. Specifically, the suit claims, in part, that generative models such as ChatGPT and GPT-4 violate copyright protections on New York Times’ content both during model training (by accessing copyrighted content for the model to learn from), and during model operation (by regurgitating memorized fragments of news articles, or by accessing news articles on the web and reproducing them in the chat interface).
The suit joins a slew of others that have been filed against AI companies over the last year. At stake here is what the legal interpretation of fair use should be in the era of generative models trained on internet-scale content. (For a primer on some of the basic copyright issues around GenAI, see our previous post). The Times claims that OpenAI’s use of its content during training is not fair use because the outputs mimic and compete with Times’ content — it’s not transformative. In response to the lawsuit OpenAI filed a blog post reiterating its stance that it believes it is fair use to datamine the vast swaths of content it has scraped online.
Courts will ultimately decide this question of fair use. Personally, I think we need to preserve fair use, perhaps for machines, but especially for people. Fair use allows us to excerpt and critique information in our own work without fear of getting sued for copyright violation. This must be preserved for a robust and civically oriented information ecosystem.
But it may, in fact, be people exercising their rights to fair use which is contributing to how OpenAI’s models memorized parts of New York Times articles. Let me explain.
In August of 2023 I systematically tried to get OpenAI models (including GPT-3 and GPT-4) to produce memorized fragments of NYT news articles. Long story short, it was pretty rare. I was only able to find reliable instances of memorization in the boilerplate of news articles. That’s because models are more likely to memorize content that’s been included in its training data many times, and that’s certainly true of boilerplate which gets repeated over and over again at the bottom of articles.
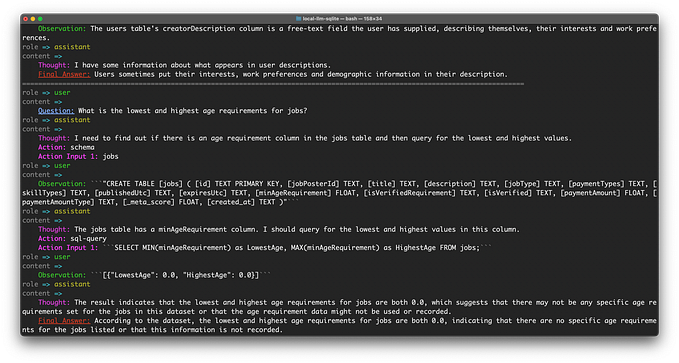
As part of its suit, the New York Times included Exhibit J, a set of 100 examples of its content where it could demonstrate memorization of that content (to some degree) by OpenAI models. For example, they might prompt the model with the first few paragraphs of an article and then the model would complete the rest of the article, often perfectly, but sometimes with a few errors here or there. So, I asked myself: Why would the New York Times include these 100 articles as exhibits? Why not any of the millions of other articles they have in their archive?
Training sets are created (in part) by trawling the internet and collecting everything that’s available. My hunch was that these 100 articles simply appear more often online, and so got swept up by OpenAI’s scraping operation multiple times. A simple web search for an article’s URL will yield an estimate of how often that URL appears online. So the hypothesis is that a web search for Exhibit J article URLs would yield more results than other articles the NYT might have picked.
To test this I used the Bing Web Search API to collect data on the number of estimated online matches for each article URL. As a baseline comparison, I used a sample of New York Times articles I had collected for my August post, a random set of 200 articles tagged in the “News” category and published between Sept 2020 and Aug 2022 in one of the following sections: U.S., World, Opinion, Business Day, Sports, Arts, New York, Style, Technology, Health, Food, and Science.
Because web search result counts are highly skewed (some articles are way more popular than the average article) I used a non-parametric statistical test to compare the distribution of estimated online matches for Exhibit J articles to the distribution of estimated online matches for the baseline articles. This Mann-Whitney test showed a statistically significant difference in the distributions (p=0.021); the median estimated number of online matches for the baseline was 276,000, and for the Exhibit J articles it was 364,000. This shows that articles in Exhibit J turned up in web searches more often than a random sample of New York Times articles.
It’s possible that Exhibit J articles got memorized because they appear more often online. And maybe that’s because people are exercising their fair use to link to and excerpt those articles and therefore more copies of those articles were swept up when OpenAI scraped the web. Additional research should examine a sample of the online matches for NYT article URLs to assess how often those reflect legitimate fair use versus perhaps other violations of copyright perpetrated against the New York Times.
Either way, this is a problem OpenAI created when they trained their model. We don’t want the New York Times clamping down on individuals exercising fair use online. But we do want OpenAI to develop better ways to filter its web scrapes. Perhaps proportionally down weighting news texts based on how often their URLs appear online would reduce memorization and violation of copyright for those articles. OpenAI could easily get this data from Microsoft. While the courts are busy with legal interpretations and the invariable appeals, perhaps this approach could reduce the immediate harm caused when generative models output text that mimics and competes with copyrighted news articles.
Generative AI models should not be permitted to replicate and reproduce content owned by another entity. But I also believe we should preserve some capacity for society to innovate by developing technologies that learn from the sum total of human communication on the internet. And we need to do that while also respecting people’s right to fair use. We should make it easy for individuals (or corporations like the Times) to withdraw their content from AI training sets (and not just opt out of future scraping). New legislation in the form of the EU AI Act should also make it easier to get some transparency into what data was used to train a generative model, and whether copyright laws were respected in the process. And, as some scholars have argued and other companies are developing, new compensation systems should be set up to reflect the value creators are providing to these models while not undermining their copyright.